Purpose
The purpose of this project was to create classifiers to categorize songs by their respective genres. Manually categorizing songs by genre can be a time-intensive and subjective process. Machine Learning appears to be applicable for genre assignment as it is a classification problem, where each category is already known. Automated genre assignment is a popular and broadly applied technology in most popular music collections such as Spotify and Apple Music.
Prior research in the realm of musical genre classification focused on content-based approaches, with an early comparative study published in 2003 indicating that the modern Daubechies Wavelet Coefficient Histograms (DWCH) method of feature extraction yielded significantly more accurate results than other existing methods [1]. Later studies used a neural network to categorize songs into predefined genre categories as we have done. These often rely on tempo, volume, and other features [2]. This project embodies many of the conditions of the latter study to build on.
Million Song Dataset
The Million Song Dataset is a collection of songs tagged with various labels, including genres, along with datasets of features extracted from the MP3 files of those songs.
The specific dataset we used from the Million Song Dataset was the Top-MAGD Million Song Dataset Benchmarks. From this dataset, we used the partition mapping files to split the feature set into testing and training data, the label assignment file, and various feature files that will be detailed in the next section. The original dataset consisted of roughly 350,000 songs but more than 200,000 of them were all from the ‘Pop_Rock’ category. This had a strong chance of leading any of our models to classify all songs as pop or rock due to the data imbalance, so we chose a stratified split, with equal entries from all genres, that would ensure the training data had an equal number of every song.
The 13 genre labels are Blues, Country, Electronic, Folk, International, Jazz, Latin, New Age, Pop Rock, Rap, Reggae, RnB, and Vocal.
Methods
All of the models were created in Python 3.7 using the library Keras with the TensorFlow backend. The output layer and loss function were common across models. The output layer consisted of a 13 node softmax activated perceptron layer. There were 13 nodes for the 13 possible genre labels and softmax was used as we were training against a one hot vector that represented the ground truth genre label. The loss function was Keras’s categorical cross entropy function, since this is categorizational problem and only a single label is applicable to any data point. This is not necessarily true for a real world application, but our data assigns a single label to each song and there is no way to apply a loss function for our model saying a song is a mix of Jazz and New Age music.
For each model below, hyperparameters were tuned manually until the model was seen to be overfitting the data. Specific parameters included the number of epochs, layer and kernel sizes, and number of layers. In general, hyperparameters were tuned such that the validation accuracy would be maximized.
Results
Perceptrons and Neural Networks
Neural network models were used on the Marsyas, JMIR, and Rhythm Histogram feature sets. Neither of these feature sets had a time component nor had an extremely large number of features. Therefore, it was decided that a simple neural network would suffice to classify songs using these features.
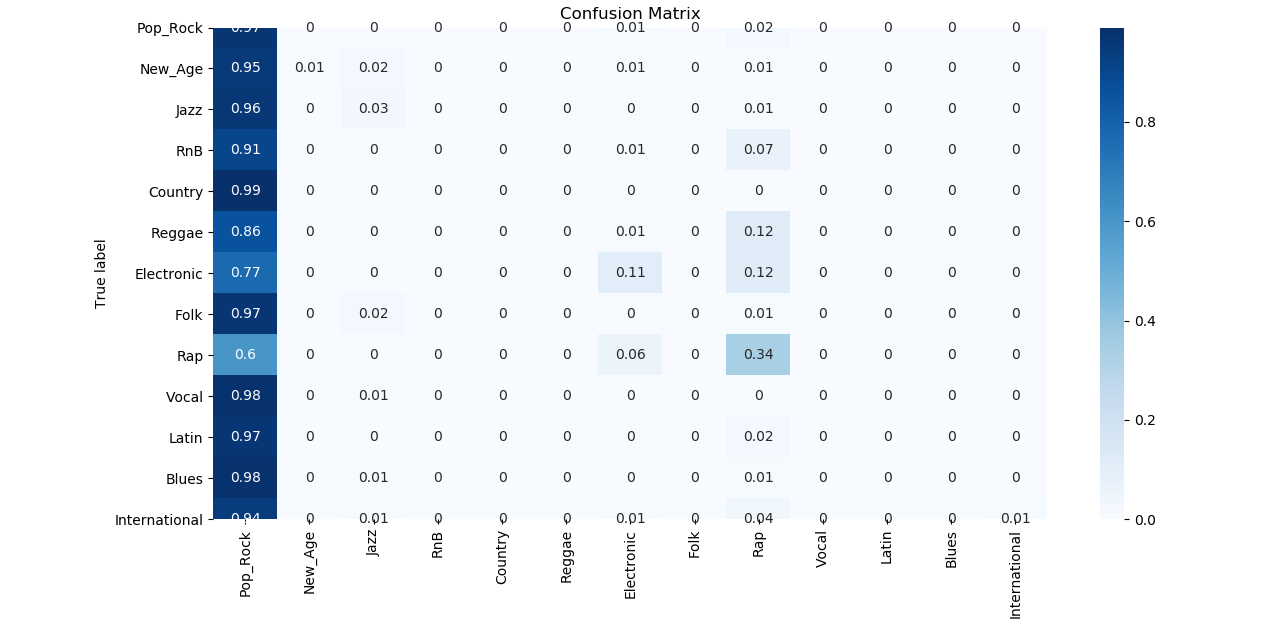
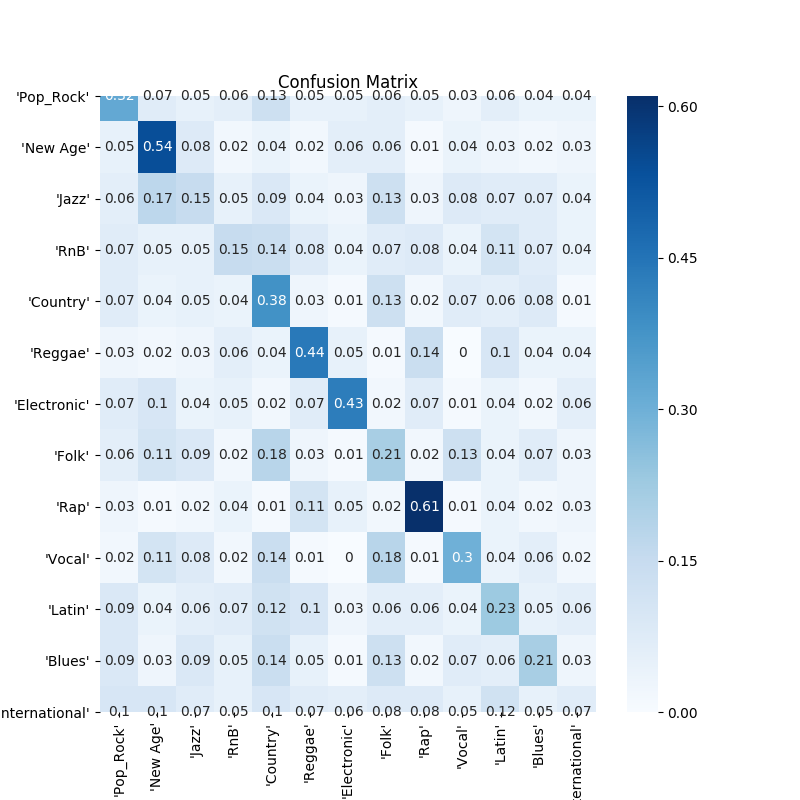
Marsyas
- Identifies and categorizes different ‘types’ of sounds in the music
- Uses the Marsyas library to analyze mp3 files
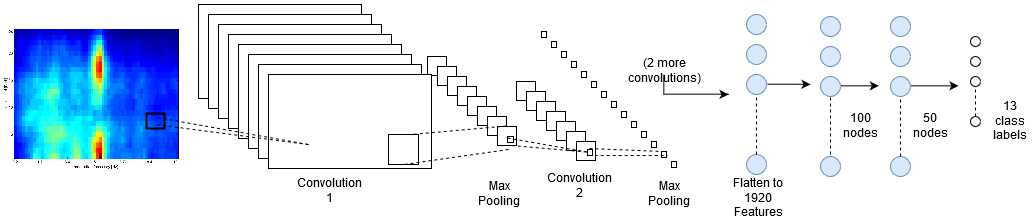
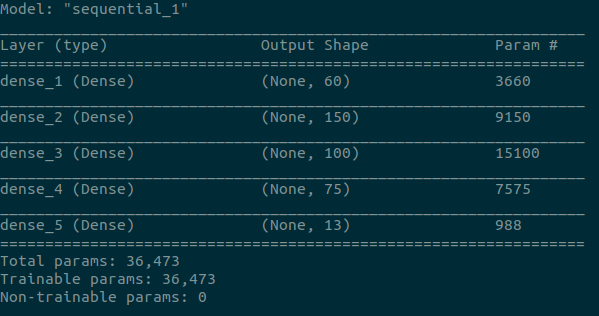
Architecture

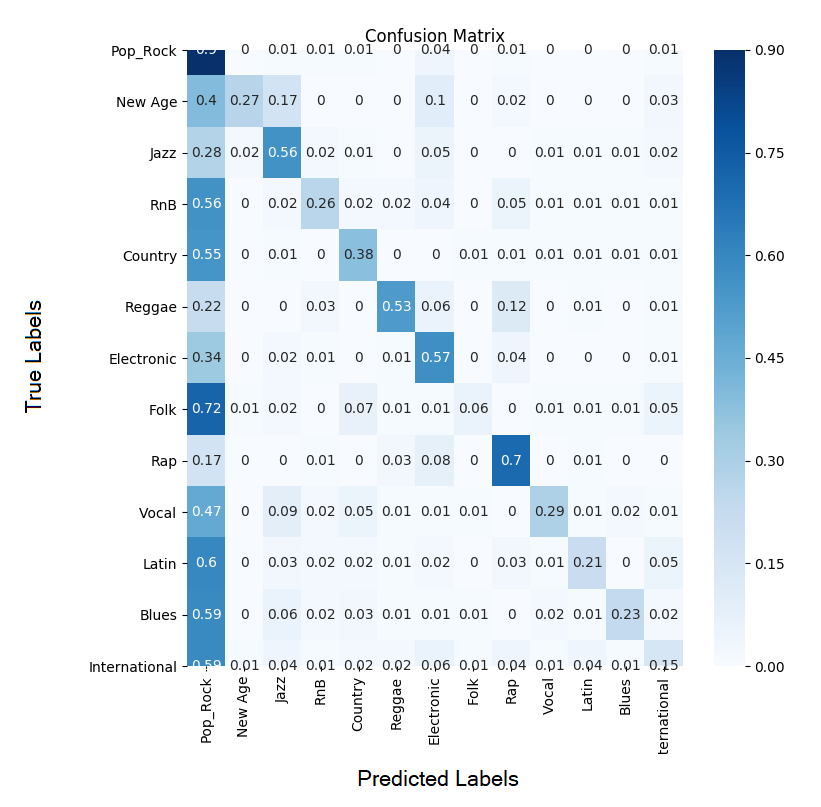
Confusion Matrix
The true label is on the y axis and the predicted label is on the x axis.
Convolutional Neural Networks
The Rhythm Pattern feature set had a total of 1,440 features for each song. A convolutional neural network was used for the rhythm patterns feature set, as a means of of extracting relevant patterns from the massive two dimensional array of features. Using a number of convolutional layers, the feature space was shrunk enough to allow for a reasonably sized neural network to analyze the resulting features.
In addition, many of these datasets included a temporal dimension that could be simplified using a kernel. Convolutional layers are known to be useful when analyzing data across a temporal dimension and we took advantage of that when presented with features spread across a temporal dimension.
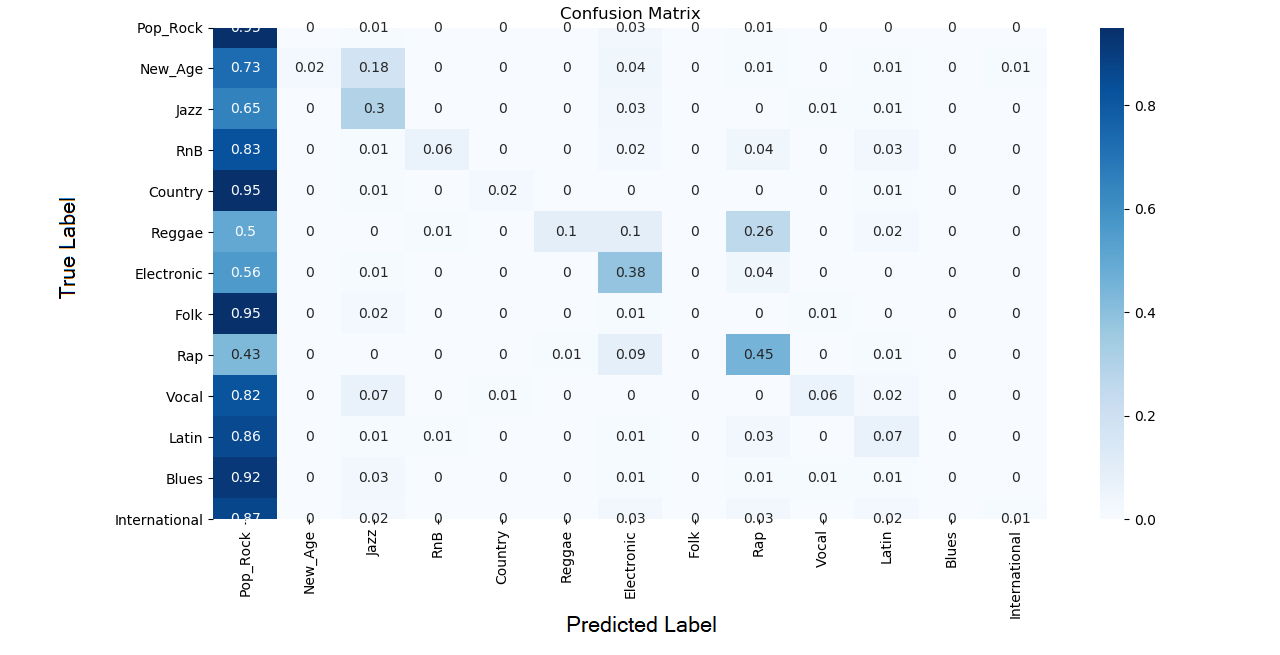
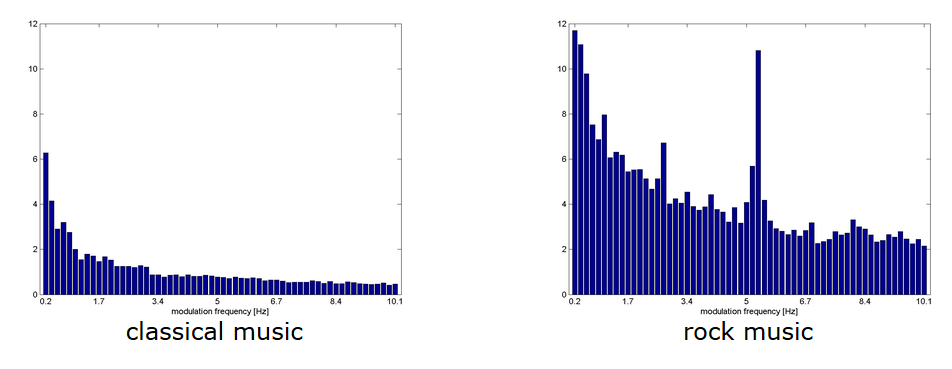
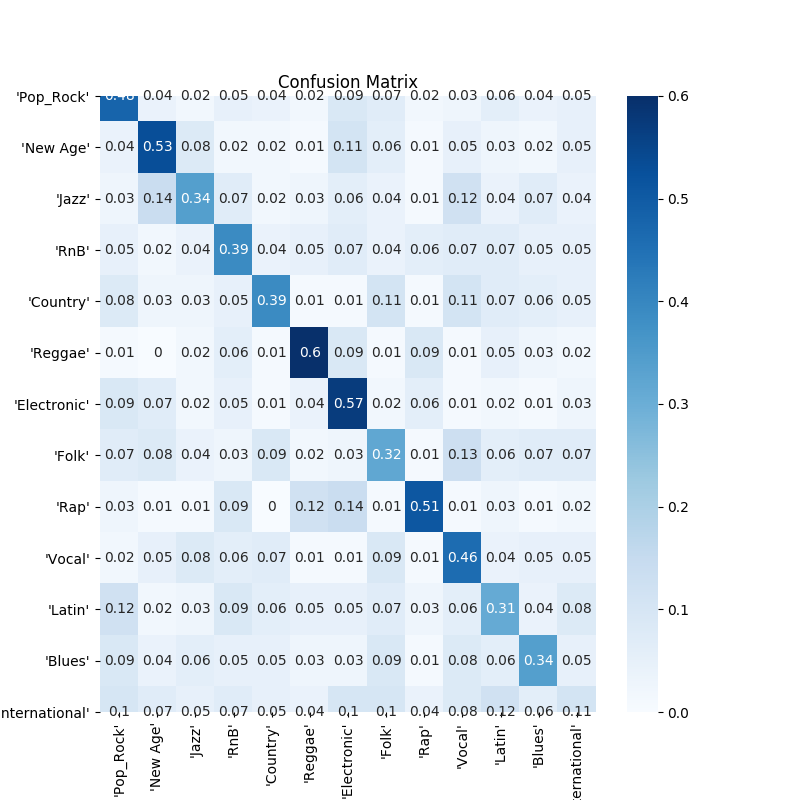
Rhythm Pattern
- Describes sound modulation across 24 frequency bands.
Architecture
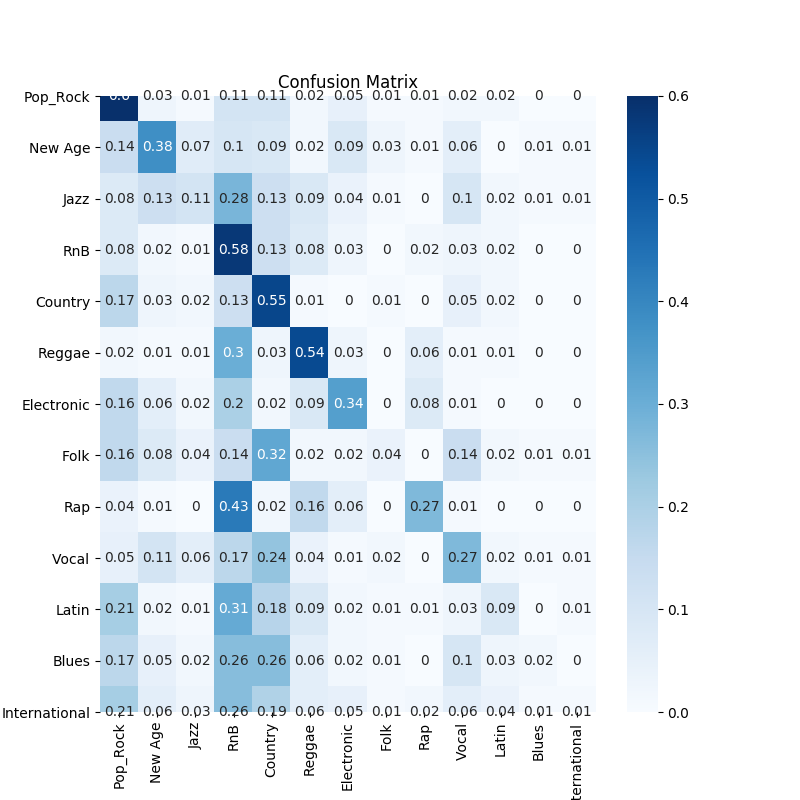
Confusion Matrix
The true label is on the y axis and the predicted label is on the x axis.

The models and architectures used for the extra features seen here can be found in Appendix B.
| Network Type | Feature Set | Accuracy(%) | Loss |
|---|---|---|---|
| Neural Network | JMIR Low Level Spectral Data | 63.5 | 1.25 |
| JMIR MFCC voice data | 67 | 1.05 | |
| Rhythm Histograms | 32.1 | 2.24 | |
| Marsyas Timbral Data | 70.1 | 0.96 | |
| Convolutional Neural Network | Rhythm Patterns | 31 | 3.8 |
| Statistical Spectrum Data | 46 | 1.8 | |
| Temporal SSD | 46 | 1.8 |
Conclusion
Given the above results, it is clear that the Marsyas Timbral data are the best features to use when classifying music genres. Many of the models would fit the training data well but struggle to achieve high accuracy across all genres with the validation data. Only the Marsyas features were able to sufficiently split the feature space into genre categories such that the boundaries worked well in both the training and validation phases. It appears that the other feature sets were not able to sufficiently partition the feature space or lacked the necessary information to discriminate between various genres.
One reason that the Marsyas features were able to classify music genre so well is that the features are composed of heavily processed information extracted from the songs. Marsyas (Music Analysis, Retrieval and SYnthesis for Audio Signals) is an audio processing library that focuses on extracting information from various signal sources and focusing on music. It is unclear how exactly the Vienna University of Technology used the library to extract information as the link is dead, but, given the above results, it seems that the Marsyas features are heavily correlated with the genre of the song and there is only minimal extra analysis needed to extract that correlation.
Future Work
The Marsyas featureset worked quite well for classifying music but lacks in its ability to classify folk music. A future project could involve feature engineering a comination dataset to take advantage of the Marsyas feature sets overall ability to classify music along with the Rhythm Pattern model’s ability to classify folk music to create a better overall classifier. Also, ensemble learning methods could be applied to reduce variance in the testing accuracy.
Appendix - Additional Feature Sets
JMIR Low Level Spectral Data
- JMIR: jAudio package for MIR (music information retrieval), equipped to extract a large variety of information from music files.
- (Spectral Centroid, Spectral Rolloff Point, Spectral Flux, Compactness, Spectral Variability, Root Mean Square, Zero Crossings, and Fraction of Low Energy Windows)
- Describes standard statistic data from sound spectrograms
Low Level Features Result
MFCC Voice Data Result
Rhythm Histogram
- Magnitudes of modulation frequency are summed over all 24 frequency bands, creating bins of the total amount of modulation at different energy levels.
- Creates bins of generally how high and low energy the rhythms are.
Architecture
Statistical Spectrum Descriptor
- Spectrograms are created with the same method of Rhythm patterns, but covering different time sections throughout the song. Statistical measures are collected over each time step and compiled into a 7x7x24 array of features.
Architecture
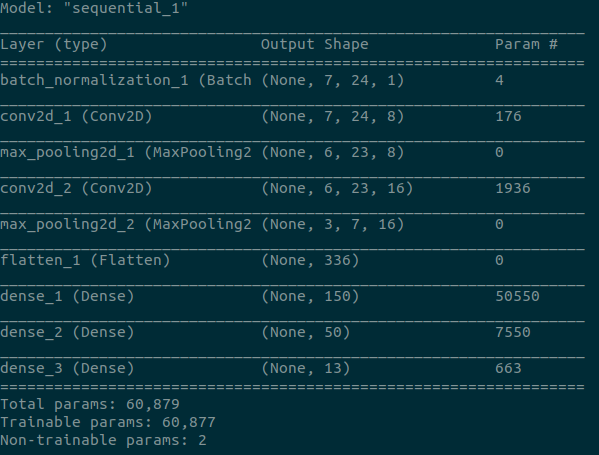
Temporal Statistical Spectrum Descriptor
- Describes changes in rhythm over time using statistical measures of multiple spectrograms.
Architecture

References
- https://dl.acm.org/citation.cfm?id=860487
- https://pdfs.semanticscholar.org/1314/aee7880cb2bc9fc20fba12264545caa45018.pdf.
- http://www.ifs.tuwien.ac.at/mir/msd/